關于MapReduce算法原理和MapReduce基本原理,以下是詳細的解釋:

1、MapReduce
MapReduce定義:MapReduce是一個分布式、并行處理的計算框架。
MapReduce產生緣由:MapReduce的產生是為了解決海量數據在單機上處理的局限性。
MapReduce與Yarn的關系:Yarn是一個資源調度平臺,負責為運算程序提供服務器運算資源,而MapReduce是運行于操作系統之上的應用程序之一。
2、MapReduce體系結構
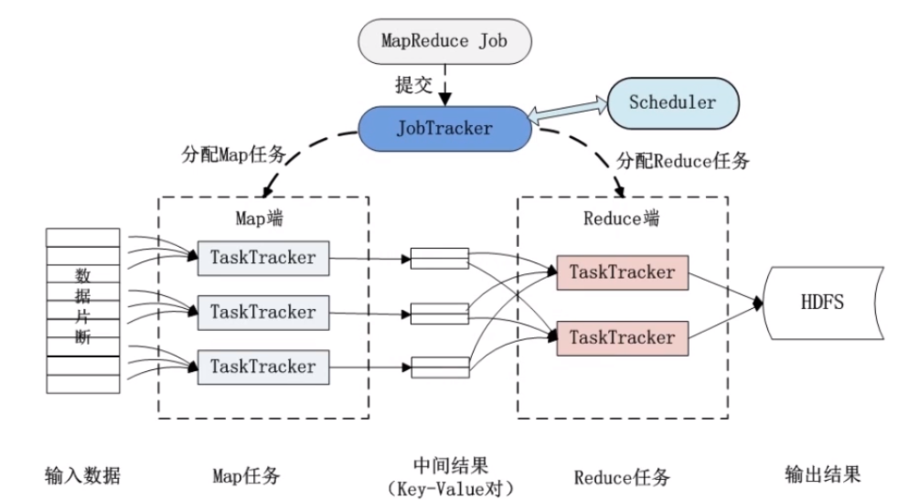
Client:用戶編寫的MapReduce程序通過Client提交到JobTracker端。
JobTracker:負責資源監控和作業調度。
TaskTracker:周期性地通過“心跳”將本節點上資源的使用情況和任務的運行進度匯報給JobTracker。
Task:Task分為Map Task和Reduce Task兩種,均由TaskTracker啟動。
3、MapReduce執行階段
Map階段:Map階段是MapReduce的第一步,負責將輸入數據集分解成一系列鍵值對。
Shuffle階段:Shuffle階段是MapReduce中的一個關鍵步驟,負責將Map階段產生的中間鍵值對按鍵進行排序和分組。
Reduce階段:Reduce階段是MapReduce的最后一步,負責將Shuffle階段產生的分區數據集合并,并將具有相同鍵的鍵值對傳遞給用戶定義的Reduce函數進行處理。
4、MapReduce核心概念
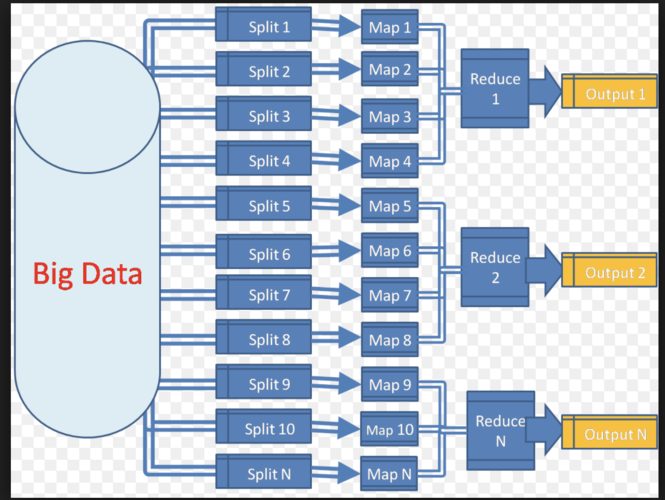
Map函數和Reduce函數:Map函數負責將獲取到的數據集進一步解析成<key,value>,通過Map函數計算生成中間結果,進過shuffle處理后作為reduce的輸入,Reduce函數得到map輸出的中間結果,合并計算將最終結果輸出HDFS。
序列化:MapReduce中的序列化使用的是Hadoop自己開發的Writable機制,精簡高效。
數據流:MapReduce中的數據流是從穩定存儲到穩定存儲的非循環數據流,這意味著數據從一個穩定的存儲介質被讀取,經過處理后再被寫入到另一個穩定的存儲介質中。
5、MapReduce工作原理
輸入:MapReduce接受輸入數據,通常以鍵值對的形式。
Map階段:輸入數據被分割成多個數據塊,每個數據塊由一個Map任務處理。
Shuffle階段:Shuffle過程包含在Map和Reduce兩端,即Map shuffle和Reduce shuffle。
Reduce階段:Reduce階段是MapReduce的最后一步,負責將Shuffle階段產生的分區數據集合并,并將具有相同鍵的鍵值對傳遞給用戶定義的Reduce函數進行處理。
6、MapReduce編程基礎
Hadoop數據類型:Hadoop有自己的數據類型,用于序列化和反序列化。
數據輸入格式InputFormat:數據輸入格式定義了如何分割數據。
輸入數據分塊InputSplit和數據記錄讀入RecordReader:InputSplit和RecordReader負責數據的分塊和讀取。
數據輸出格式OutputFormat:OutputFormat定義了如何輸出數據。
數據記錄輸出類RecordWriter:RecordWriter負責將數據寫入到指定的輸出格式。
Mapper類和Reduce類:Mapper類和Reduce類是需要用戶自定義的類,用于實現具體的映射和歸約邏輯。
構成了MapReduce算法原理和MapReduce基本原理的詳細解釋,希望這些信息能夠幫助您更好地理解MapReduce的概念和工作機制。